No es un secreto que las aplicaciones de hoy en día generan una gran cantidad de datos y sumado a eso, cada vez tenemos más aplicaciones independientes que van produciendo datos de forma aislada, por tal motivo, llegara un momento en que los datos están distribuidos en varias base de datos, por lo que recuperar información relevante y consistente, nos obliga a crear complejos procesos de extracción y cargado de datos (ETL) para integrarlos en una única fuente confiable para finalmente sea analizada y explotable, sin embargo, como analizaremos en este artículo, este enfoque tiene grandes problemas, entre los que destaca los complicados procesos de extracción y los múltiples procesos ETL que deben de correr una y otra vez para obtener diferente información para diferentes análisis o reportes.
as Una de las grandes ventajas que tiene trabajar con JPA, es que te permite hacer relaciones con otras entidades, de esta forma, es posible agregar otras Entidades como atributos de clase y JPA se encargará de realizar el SELECT adicional para cargar esas Entidades.
Una de las grandes ventajas que tiene trabajar con JPA, es que te permite hacer relaciones con otras entidades, de esta forma, es posible agregar otras Entidades como atributos de clase y JPA se encargará de realizar el SELECT adicional para cargar esas Entidades.  Hasta el momento solo hemos trabajado con el Entity Manager para realizar las operaciones básicas, pero existen detalles más finos que es necesario entender para convertirnos en expertos de JPA. Cuando trabajamos con JPA es común interactuar con el Entity Manager, ¿pero que tanto sabemos acerca de los Persistence Context en realidad?
Hasta el momento solo hemos trabajado con el Entity Manager para realizar las operaciones básicas, pero existen detalles más finos que es necesario entender para convertirnos en expertos de JPA. Cuando trabajamos con JPA es común interactuar con el Entity Manager, ¿pero que tanto sabemos acerca de los Persistence Context en realidad?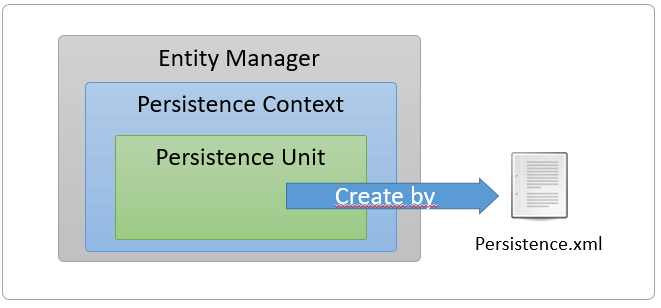
 JTA o Java Transaction API es la encarga de administrar las transacciones del lado del servidor, abstrayendo casi en su totalidad al programador de abrir o cerrar las transacciones, de esta forma el programador únicamente se preocupa por la lógica de negocio aumentando drásticamente la productividad y los errores de Runtime.
JTA o Java Transaction API es la encarga de administrar las transacciones del lado del servidor, abstrayendo casi en su totalidad al programador de abrir o cerrar las transacciones, de esta forma el programador únicamente se preocupa por la lógica de negocio aumentando drásticamente la productividad y los errores de Runtime.  Una parte esencial de utilizar JPA es saber utilizar las operaciones básicas, operaciones mediante las cuales es posible consultar, persistir, actualizar y eliminar entidades, de estas operaciones estaremos hablando hoy.
Una parte esencial de utilizar JPA es saber utilizar las operaciones básicas, operaciones mediante las cuales es posible consultar, persistir, actualizar y eliminar entidades, de estas operaciones estaremos hablando hoy.