
 La escalabilidad es la capacidad del software para adaptarse a las necesidades de rendimiento a medida que el número de usuarios crece, las transacciones aumentan y la base de datos empieza a sufrir degradamiento del performance por las cargas crecientes.
La escalabilidad es la capacidad del software para adaptarse a las necesidades de rendimiento a medida que el número de usuarios crece, las transacciones aumentan y la base de datos empieza a sufrir degradamiento del performance por las cargas crecientes.
Hoy en día es muy común escuchar a los arquitectos de software que su solución es robusta, segura y escalable (Si cómo no!!!), pero la realidad es que pocas aplicaciones están realmente preparadas para ser escaladas, ya que desde su diseño de arquitectura no fueron concebidas para soportarlo o realmente no está muy claro que es realmente escalamiento.
Como ya dijimos, el escalamiento es la capacidad del software para adaptarse al creciente número de usuario, transacciones, etc. ¿pero como un sistema se puede preparar para crecer indeterminadamente? La realidad es que las aplicaciones no pueden crecer infinitamente, por lo que siempre es clave determinar desde el diseño el grado de escalamiento que una aplicación podrá soportar, ya que por más estrategias que utilicemos el sistema ya no dará más.
Puede que los algoritmos utilizados no se puedan optimizarse más o la arquitectura no fue diseñada para un volumen tan alto de carga. Por otro lado, podríamos agregar más memoria al servidor, mas disco duro, cambiar a SSD, poner más cores, mejorar el enfriamiento, etc, etc. Sin embargo, llegara un momento que el hardware no puede crecer más, y tus sistemas simplemente explotaran, tendrás a los directores encima de ti preguntando cada 5 min ¿Qué paso? Y ¿En cuando tiempo quedarán listos los sistemas? El negocio está detenido, no podemos vender, los clientes están enojados, etc, etc, hasta el punto que tú mismo explotes con el sistema (hipotéticamente).
Escalabilidad Horizontal y Vertical
En la práctica existen muchas formas de hacer que un software sea escalable ya que podemos combinar técnicas de software y hardware e incluso arquitecturas de RED (por qué no), pero en esta ocasión me quiere centrar en la escalabilidad horizontal y vertical, porque sin duda es una de las características más importantes para sistemas de alta demanda o uso crítico.
Bien, como ya dijimos existen dos tipos de escalamiento, Horizontal y Vertical, ¿pero que quiere decir cada uno?
Escalabilidad vertical
La escalabilidad vertical o hacia arriba, este es el más simple, pues significa crecer el hardware de uno de los nodos, es decir aumentar el hardware por uno más potente, como disco duro, memoria, procesador, etc. pero también puede ser la migración completa del hardware por uno más potente. El esfuerzo de este crecimiento es mínimo, pues no tiene repercusiones en el software, ya que solo será respaldar y migrar los sistemas al nuevo hardware.
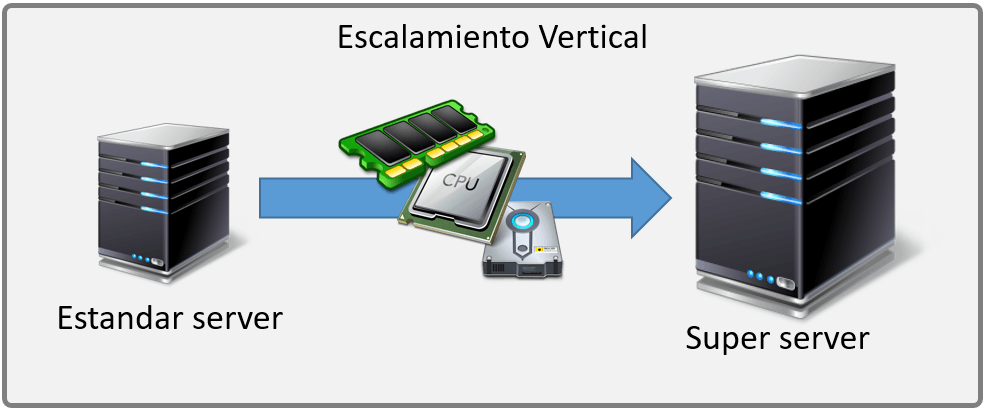
¿Bastante fácil no?, la realidad es que este tipo de escalamiento tiene algunos aspectos negativos, ya que nuestro crecimiento está ligado al hardware, y este; tarde o temprano tendrá un límite, llegara el momento que tengamos el mejor procesador, el mejor disco duro, la mejor memoria y no podamos crecer más o podríamos a lo mejor comprar el siguiente modelo de servidores que nos costara un ojo de la cara y el rendimiento solo mejorar un poco, lo que nos traerá el mismo problema el próximo año.
Ahora bien, no significa que este modelo de escalamiento sea malo, ya que lo podemos combinar con el escalamiento horizontal para obtener mejores resultados.
Ventajas:
- No implica un gran problema para las aplicaciones, pues todo el cambio es sobre el hardware
- Es mucho más fácil de implementar que el escalamiento horizontal.
- Puede ser una solución rápida y económica (compara con modificar el software)
Desventajas:
- El crecimiento está limitado por el hardware.
- Una falla en el servidor implica que la aplicación se detenga.
- No soporta la Alta disponibilidad.
- Hacer un upgrade del hardware al máximo pues llegar a ser muy caro, ya que las partes más nuevas suelen ser caras con respecto al rendimiento de un modelo anterior.
Escalabilidad horizontal
El escalamiento horizontal es sin duda el más potente, pero también el más complicado. Este modelo implica tener varios servidores (conocidos como Nodos) trabajando como un todo. Se crea una red de servidores conocida como Cluster, con la finalidad de repartirse el trabajo entre todos nodos del cluster, cuando el performance del cluster se ve afectada con el incremento de usuarios, se añaden nuevos nodos al cluster, de esta forma a medida que es requeridos, más y más nodos son agregados al cluster.
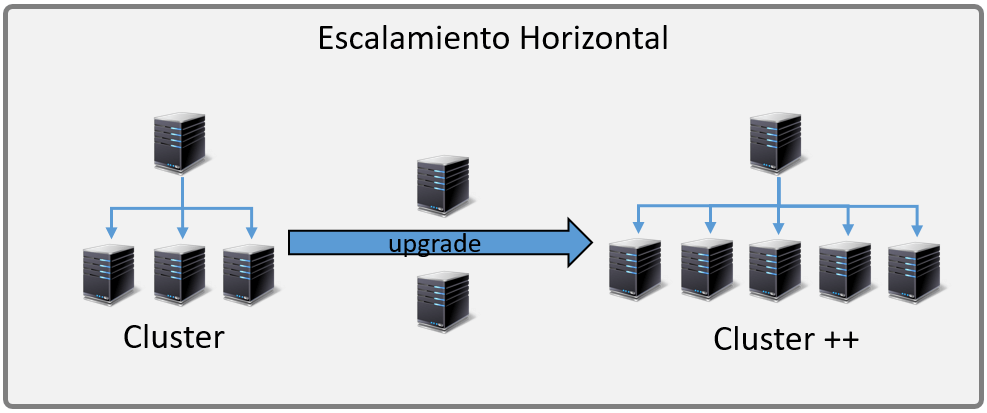
Para que el escalamiento horizontal funcione deberá existir un servidor primario desde el cual se administra el cluster. Cada servidor del cluster deberá tener un software que permite integrase al cluster, por ejemplo, para las aplicaciones Java, tenemos los servidores de aplicaciones como Weblogic, Widfly, Websphere, etc. y sobre estos se montan las aplicaciones que queremos escalar.
Ventajas:
- El crecimiento es prácticamente infinito, podríamos agregar cuantos servidores sean necesarios
- Es posible combinarse con el escalamiento vertical.
- Soporta la alta disponibilidad
- Si un nodo falla, los demás sigue trabajando.
- Soporta el balanceo de cargas.
Desventajas:
- Requiere de mucho mantenimiento
- Es difícil de configurar
- Requiere de grandes cambios en las aplicaciones (si no fueron diseñadas para trabajar en cluster)
- Requiere de una infraestructura más grande.
Failover
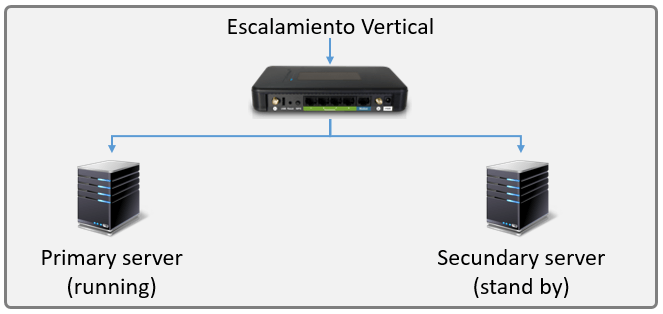
A pesar de que escalamiento vertical no soporta de forma natural la alta disponibilidad, sí que es posible habilitarla mediante una estrategia llamada Failover, la cual consiste en que cuando el servidor falla, mediante hardware se redireccionan las peticiones a un servidor secundario que es un espejo del principal, este servidor normalmente se encuentra en stand by, y solo se habilita cuando el primario falla, de la misma manera, cuando el primario se recupera, el secundario vuelve a pasar a stand by.
Por otra parte, la escalabilidad horizontal ya utiliza de forma natural el Failover, ya que al haber varios nodos, es posible pasar la carga al resto de nodos activos en caso de que uno falle. Ahora bien, esto no garantiza una alta disponibilidad total, ya que si el servidor primario falla puede tumbar todo el cluster, por lo que también se suele utilizar un ambiente espejo del cluster para garantizar la alta disponibilidad. Cabe mencionar que esto solo lo hacen empresas gigantes, ya que administrar dos cluster completos es un verdadero reto.
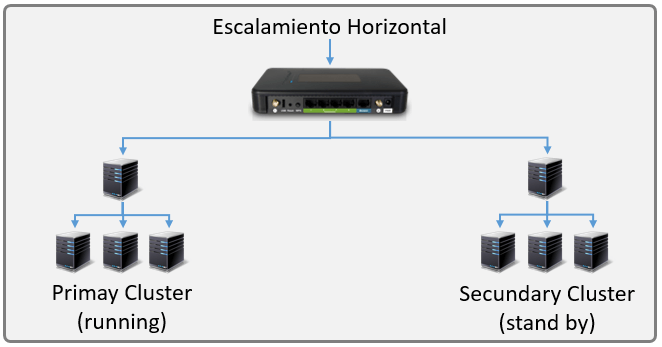
Failover
Hoy en día que las aplicaciones son parte fundamental de las empresas y que la falla en ellas puede incluso detener la operación de la empresa, llevándolas a perder grandes cantidades de dinero, es por eso que sumamente importante tener en mente el escalamiento de la aplicaciones y siempre tener un plan B en caso de que estas fallen, ¿Te imaginas la cantidad de dinero que perdería por hora, si la página de Amazon se callera? probablemente millones. Es por eso que debemos de estar preparados para escalar nuestras aplicaciones.
Si en este punto aun no estás seguro que escalamiento te va mejor, puedes analizar lo siguiente, si tu aplicación es de baja demanda y el número de usuarios está pensado para crecer poco a poco, la mejor solución puede ser el escalamiento vertical, ahora, si esta misma aplicación a pesar de su poco crecimiento es crítica para el negocio, entonces la puedes combinar con Failover para asegurar la alta disponibilidad.
Por otra parte, si tu aplicación esta pensaba para un crecimiento acelerado y crees que un servidor pueda quedar chico en un corto o mediano plazo, lo mejor será que empieces a pensar en escalamiento horizontal. Ahora bien si además del crecimiento la aplicación es de uso crítico, lo mejor será implementar un Failover. Si ya está utilizando escalamiento horizontal, recuerda que también puedes realizar escalamiento vertical a cada nodo del cluster, siempre y cuando el escalamiento vertical resulte más económico que agregar un nodo más.
Bueno, esas son mis conclusiones, que piensas ahora, ¿estas realmente preparado para el desastre?
Hola Oscar, Soy Arquitecto de Aplicaciones y me encanta tu. log. En realidad pienso que redactas muy bien y sabes de lo que hablas. Te felicito
Hola Andrés, muchas gracias por tus comentarios, es bueno escuchar de vez en cuando que el contenido que genero es de utilidad, eso me motiva a seguir.
Espero que ya estés suscrito al blog para que puedas recibir todas las actualizaciones.
saludos.
esto tambien aplica para las bases de datos relacionales?
Hola Juan, esa es una muy buena pregunta.
La respuesta es SI y NO. si bien, gran parte de la teoría descrita aquí puede aplicar, la verdad es que las estrategias para las bases de datos se implementan un poco diferente, pues la estrategia de los servidores y aplicaciones es dividir la carga en varios servidores, los cuales procesan de forma independiente, por lo que nos les importa que pase con los otros nodos del cluster. Por otra parte, las bases de datos, tiene la diferencia que al final, la información debe estar centralizada, pues dividir la información no es una opción, porque está relacionada. Pero si se puede dividir la información por regiones, de tal forma que cada región opere con una base de datos distinta y al final del día o en algún momento corran procesos para recuperar información de las distintas regiones.
Espero que esta respuesta sea lo que esperabas, si no, no dudes en volver a preguntar.
El nodo central haria el papel de balanceador de carga?? o el balanceador de carga iria abajo del nodo central, esta parte me causa duda espero puedas responder pronto muy buen blog
Hola Francisco, todo dependerá de como este organizado tu arquitectura de servidores, sin embargo, por lo general, el balanceador de cargar se expone por Internet como un punto de acceso único, y luego el balanceador es el que direccionamiento las peticiones a un servidor u otro. En este caso, el balanceador esta por enésima del nodo central.
El nodo central no es un servidor al cual le hagamos peticiones, si no más bien, es el encargado de mantener un coherencia entre el cluster, es decir, desde allí se puede administrar, monitorea y se encarga de sincronizar cierta información con todos los nodos. Es por esta razón que cualquier nodo puede recibir peticiones de forma independiente, si pasar por el nodo central, sin embargo, el nodo estará notificando al nodo central de todo lo que pasa, con la finalidad de que el nodo central puede replicarlos al resto de nodos.
Muchas gracias. Excelente blog.
Gracias por tus comentarios, es un placer saber que el material que comparto es de utilidad.
saludos.
Muchas gracias, excelente explicación.
Gracias Samuel, es un gusto saber que es de utilidad, saludos. 🙂
Muy buen articulo! Queda bastante clara la diferencia entre los dos tipos de escalado y el caso fatídico en el que el escalado vertical ya no sirve de nada. Lo dicho, gran aportación! 😁😁
Gracias por el comentario Jiaquin 🙂
Hola
Muy buen articulo, de echo me suscribí para seguir su blog. Me surgió una duda en un punto en especial:
“Requiere de grandes cambios en las aplicaciones (si no fueron diseñadas para trabajar en cluster)”. Podria darme una “luz” para investigar las directrices para un diseño de software que aguante cluster?.
Muchas gracias saludos !
Hola Jorge,
Me gustaría darte un link pudieras revisar alguna guía, pero no logro encontrar una que me agrade, por lo que te voy a comentar rápidamente.
En realidad hay muchos pequeños detalles que se tiene que cuidar, pero hablar de ellos podría extenderse mucho.
Disculpa la molestia, Oscar. Mi hijo esta estudiando Ingeniería de Sistemas y quisiera que me recomendaras una Netbook o Notebook para su especialización en Big Data. Muchas gracias.
Hola Jorge, lamento no poder ayudarte, el hardware no es mi especialidad, incluso, debo reconocer que yo mismo batallo para elegir un equipo. Sin embargo, trataré de darte algunas características del hardware que yo elegiría para lo que me mencionas.
Primero que nada, el procesamiento de BigData es pesado, pero solo si realmente de trabajar con volúmenes muy grandes de información, si tu hijo está estudiando, es muy posible que trabaje con volúmenes de datos “manejables”, por lo que quizás un equipo con un Intel i5 y unos 8gb de RAM sería bastante bueno, adicional, podrías incluirle un disco de estado solido (SSD) que ayuda a recuperar la información más rápido desde el disco, algo muy importante para el BigData.
Quizás y basado en tu presupuesto, podrías adquirir algo superior, como un Intel i7 y 16gb de RAM, pero eso te lo dejo a tu criterio.
saludos.
Pero que interesante blog y todo se entiendo a la perfeccion. Soy estudiante de la Lic. en informatica y esta area de la informatica es lo que me ha llamado la atencion ultimamente.Actualmente estoy tomando un curso en big data y posteriormente voy a tomar un diplomado en esta area tambien.
La verdad es que si,me llama la atencion.Quiero aparender mucho. ¿Acaso me recomiendas algun que otros recursos en esta travesia de aprendizaje?
Hola Luis, pues es que hay tantas cosas por aprender que es dificil darte una ruta de aprendizaje, mas bien yo te preguntaría que cosas te gustaría lograr, para sobre eso darte alguna recomendación.
Saludos.
Excelente blog, al fin logre entender bien lo de la escalabilidad.
Quisera saber si me puderas dar bibliografia para seguir avanzando en este tema.
Gracias.
Hola Antonino, este artículo cubre la teoría, para profundizar, tendrías que hacerlo ya con una herramienta concreta pero no se que tecnologías domines, en el caso de Java, podrías estudiar como hacer un cluster con Wildfly o Payara server y para eso debería haber algunos libros en Amazon.
Excelente post. Lo encontré estudiando para un examen de Arquitectura de Software y la verdad me apasionó continuar leyendo aún luego de haber encontrado la respuesta a la pregunta que necesitaba.
Muy claras tus ideas y muy bien expresadas.
Gracias!
Gracias por el comentario Fabian 🙂
Me ha gustado mucho el artículo y explicas muy bien cada pro y contra. Gracias por compartirlo.
No hay que, te mando un saludo