

Una gran parte de las aplicaciones que se construyen hoy en día, requieren de un API para funcionar, dicha API ofrece todos los servicios necesarios para que la aplicación puede interactuar con el Backend y así afectar la información de la base de datos, sin embargo, de esa gran cantidad de aplicaciones que se conectan con APIs, requieren saber exactamente donde está alojado (IP y puerto) cada uno de los servicios que conforman el ecosistema de microservicios, es allí donde entra el Service Discovery pattern para solucionar ese tipo de dependencias.
Arquitectura tradicional
Para comprender exactamente cómo funciona el patrón Service Discovery es necesario entender cómo es que las aplicaciones que se conectan a un API normalmente:
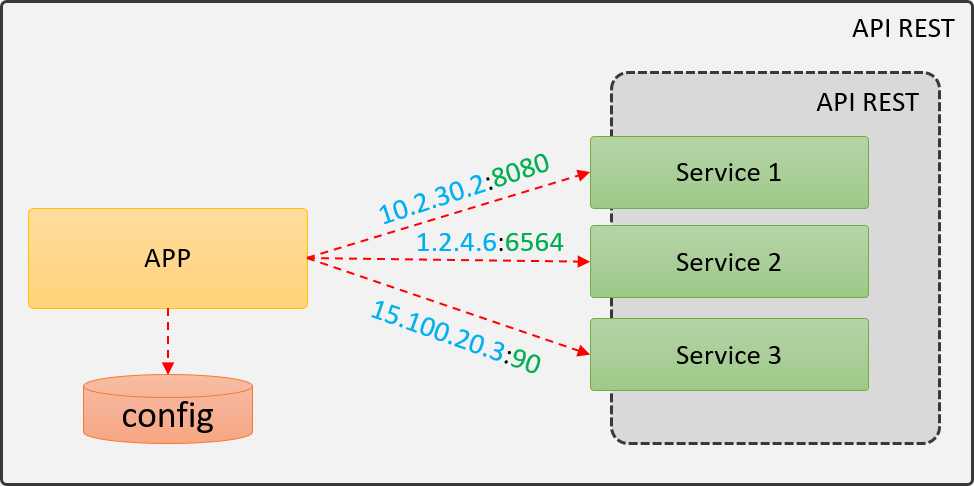
Si analizamos la imagen anterior, nos podemos dar cuenta que la aplicación (APP) requiere leer una configuración local para saber dónde están alojados los servicios, este almacenamiento puedes ser un archivo de propiedades, una base de datos local o cualquier medio de persistencia. Una vez que la aplicación sabe dónde están los servicios, entonces ahora si realiza una llanada a ellos.
Una vez analizada la arquitectura pasada, veamos qué pasa si más aplicaciones son dependientes de los mismos servicios:
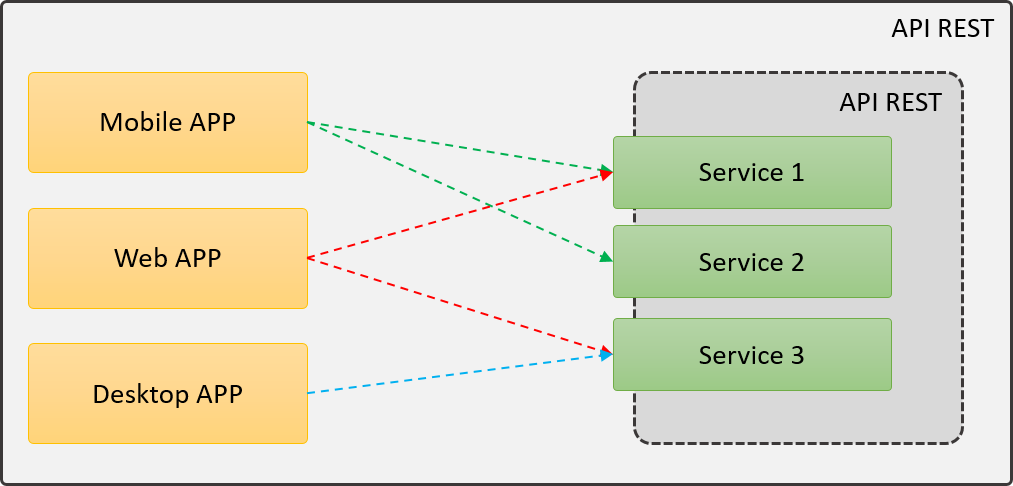
En esta arquitectura podemos ver que tenemos 3 aplicaciones que dependen de los mismos servicios, y cada uno de ellos tiene su configuración para determinar dónde están los servicios. Ahora imagina que algún servicio cambia de puerto o de dirección IP, lo cual es muy frecuente en una arquitectura Cloud donde la IP es flotante.
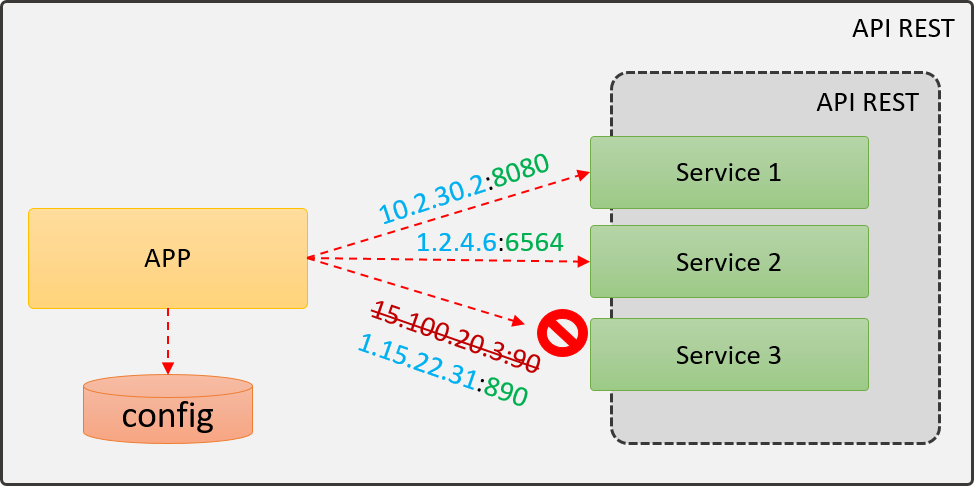
Tras cambiar la dirección (IP y puerto) del servicio, la aplicación empezará a fallar de forma inmediata, pues en su configuración le seguirá diciendo que el servicio está todavía en la antigua dirección, lo que nos obligará a cambiar a actualizar la configuración en todas las aplicaciones para apuntar a la nueva ruta del servicio.
Por otro lado, tenemos el caso de que tengamos más de una instancia del mismo servicio:

En estos casos, es posible que optemos por meter un balanceador de cargas, de tal forma que nosotros solo necesitamos comunicarnos con él, y será el balanceador quien finalmente reenvíe la petición a la instancia correspondiente. Este escenario es bastante prometedor y muchas aplicaciones funcionan así, pero aquí también tenemos el problema anterior, ¿qué pasa si una instancia cambia de dirección?, en este escenario no habría tanto problema, porque el balanceador redirigiría la petición a otra instancia, pero entonces ya solo nos quedamos con dos instancias operando, para resolver este problema, un administrador de servidores tiene que ir a la configuración del balanceador de cargas y actualizar con la nueva dirección del servicio. Como podemos ver, en esta arquitectura estamos más protegidos contra la falla o cambio de dirección de una instancia, sin embargo, el problema de la ruta física del servicio continua allí.
Y finalmente, el escenario más interesante de todos, imagina que tu arquitectura está funcionando muy bien, nada está fallando, pero el número de usuarios está en alza y requieres agregar una nueva instancia para soportar la carga, en tal caso tendrías que levantar una nueva instancia del servicio y nuevamente actualizar el balanceador de cargas para agregar el nuevo servicio.
Puede que esta arquitectura no tenga nada de extraño, incluso, es posible que algunas de las aplicaciones que estamos actualmente desarrollando estén configuradas de esta forma, pero entonces ¿qué tiene de malo utilizar esta arquitectura? Esta arquitectura no es que sea precisamente mala, pero tiene grandes inconvenientes que se acentúan a medida que migramos a una arquitectura de microservicios y tenesmos cada vez un número más grande de servicios, incluso, podemos tener más de una instancia de cada servicio.
Service Discovery pattern
Qué pasaría si no fuera necesario indicar en nuestras aplicaciones donde están físicamente los servicios y que, en lugar en su lugar, sean los mismos servicios que nos digan donde están físicamente, pues bien, eso es precisamente lo que nos propone el patrón Service Discovery.
La idea central de esta patrona es que todos los servicios cuando inician, se registran ante una entidad llamada Service Registry, el cual lleva el control de todos los servicios activos. De tal forma que cuando nosotros queremos consumir un servicio, buscamos en el Service Registry las instancias disponibles. Suena extraño esto que estoy diciendo, pero vallamos por partes, veamos como un servicio se registra:
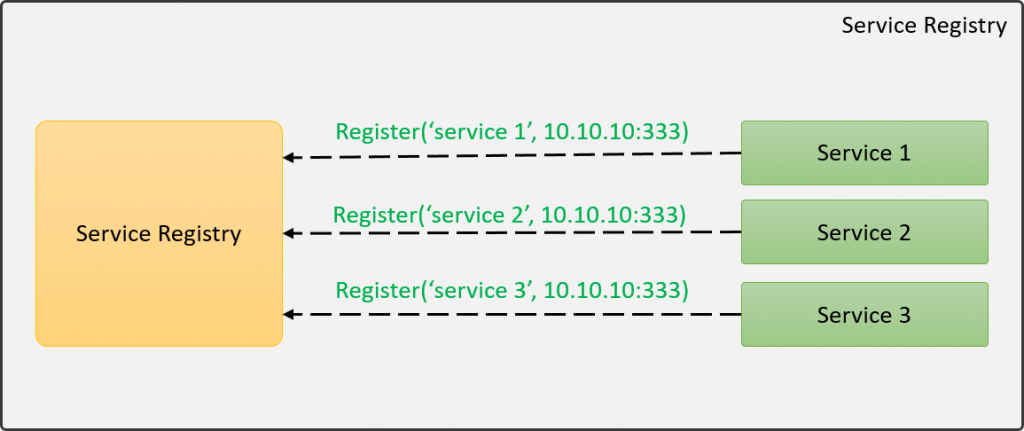
En la imagen se puede apreciar como cada servicio se registra de forma individual, indicándole por lo menos, su nombre y la dirección en la que se encuentra el servicio, de esta forma, el Service Registry tiene un registro de todos los servicios que están disponibles. Adicional al registro inicial, los servicios tienen que mandar señales de vida cada X tiempo para que el Service Registry sepa que el servicio continúa disponible, ha esto se le conoce como heartbeat (latidos).
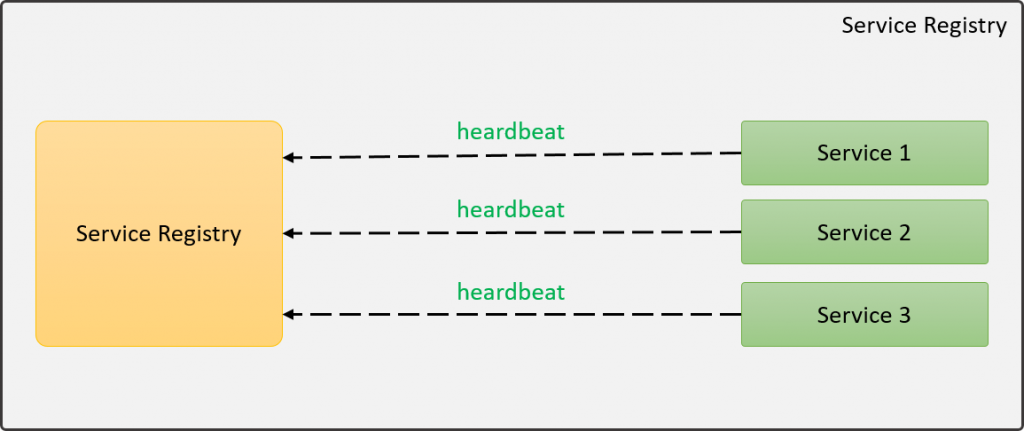
Si un servicio no se reportar (heartbeat), el Service Registry sabrá que hay algo mal en ese servicio y asumirá que no está disponible, por lo que todas las peticiones serán redirigidas a las demás instancias. Adicional, es posible que el Service Registry nos mande notificaciones cuando un servicio no está disponible para poder actuar en consecuencia.
Ya que hemos comprendido que es un Service Registry, continuaremos hablando del patrón Service Discovery. Este patrón nos permite ejecutar un servicio determinado sin conocer la dirección física del servicio, para esto, utilizamos un balanceador de cargas que se apoyará del Service Registry para conocer la ubicación real del servicio.
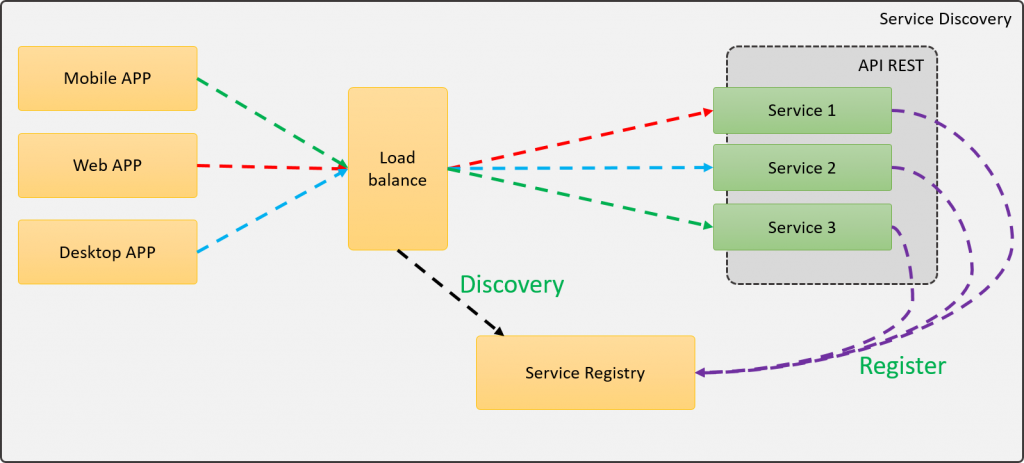
Esta nueva arquitectura funciona de la siguiente manera, primero que nada, los servicios se registrarán ante el Service Registry, con la finalidad de saber qué servicios tenemos disponibles, por otra parte, los clientes ejecutarán llamadas a los servicios por medio del balanceador de cargas, el cual se apoyará del Service Registry para determinar la dirección física del servicio y redireccionar la petición a la instancia correcta del servicio.
En esta nueva arquitectura, podemos ver los componentes que ya conocíamos, como los servicios, el Service Registry, el Balanceador de cargas y los clientes, por lo que seguramente te estés preguntando, que tiene de diferente esta arquitectura con la que hablamos al principio. Bueno la diferencia es muy grande, aunque de entrada no quede muy clara. Para empezar, ya no tenemos la necesidad de conocer la dirección física de los servicios, pues ellos mismo se registran al iniciar y nos permite saber su estado mediante el heartbeat, por otro lado, si aprovisionamos una nueva instancia de un servicio, este se registrará de forma automática ante el Service Registry, por lo que no habrá necesidad la configuración de ningún componente.
Por otro lado, el balanceador de cargas puede estar ubicado en dos puntos diferentes, a estas dos variantes se les conoce como Server-Side (del lado del servidor) o Client-Side (del lado del cliente). Debido a que cada uno tiene sus ventajas y desventajas, las analizaremos por separado:
Client-Side
En esta variante, el balanceador de cargas se ubica directamente sobre la aplicación, de tal forma que no requiere realizar una llamada remota al balanceador, en su lugar, la implementación local del Balanceador se comunicará con el Service Registry para obtener las instancias disponibles, y luego, desde la misma aplicación, se seleccionará la instancia a ser consumida.
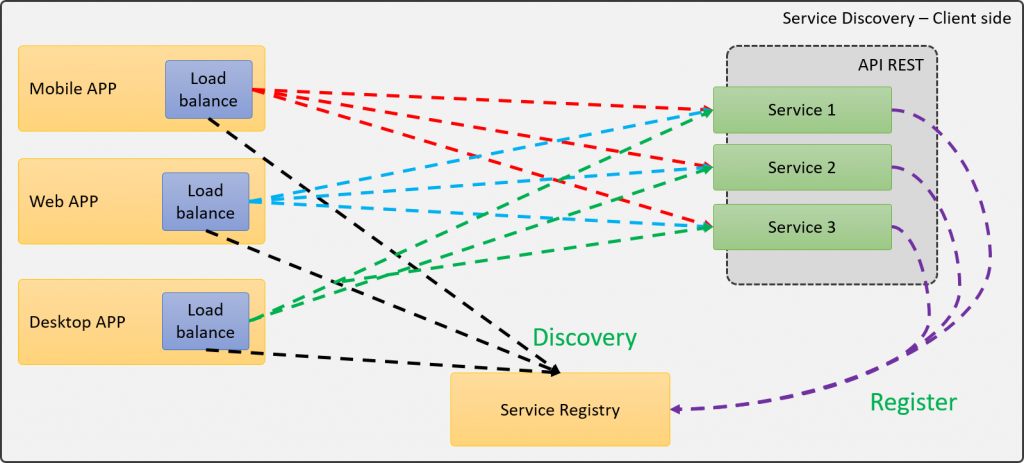
Esta arquitectura puede verse algo confusa, pues parece un plato de espagueti, ya que cada aplicación se puede comunicar directamente con cada instancia de los servicios disponible, provocando que visualmente se vea más complicado de lo que parece.
Ventajas
- No existen tantos puntos móviles, lo que evita tener que depender un balanceador externo.
- Es más fácil de administrar, pues no es necesario administrar un balanceador externo
- Dado que cada cliente implementa su propio balanceador, se evita un único punto de fallo.
Desventajas
- Debido a que se une el cliente con el balanceador, hay que implementar el balanceador en cada aplicación que sea necesario.
- Es necesario implementar la lógica de descubrimiento de servicios en el cliente.
Server-Side
En esta arquitectura, el balanceador de cargas es un componente externo, al cual todos los clientes se conectan, de esta forma, cuando una petición llega, el balanceador será el encargado de buscar la instancia adecuada por medio del Service Registry.
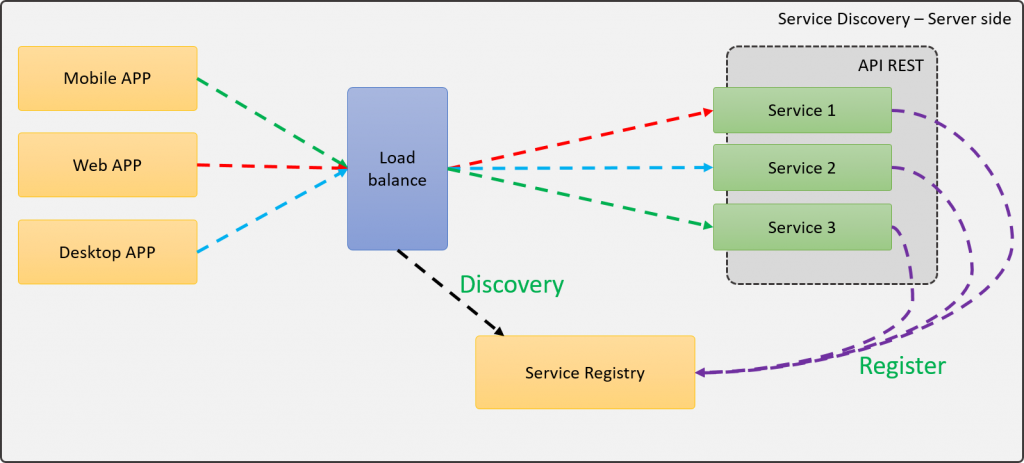
Esta arquitectura es visiblemente más limpia, pues los clientes solo se comunican con el balanceador de cargar y él se encargará se redirigir la petición al servicio adecuado. En esta arquitectura, el cliente no se preocupa por el descubrimiento de los servicios ni de balancear la carga entre las diferentes instancias de un mismo servicio. Adicional, es posible tener un cluster de Balanceadores de carga para evitar un único punto de fallo.
Ventajas:
- Desacoplamos la responsabilidad del balanceo y descubrimiento de servicios por parte del cliente
- Evitando tener que desarrollar esta funcionalidad en cada cliente.
Desventajas:
- Es necesario administrar el balanceador de cargar, lo que puede llevar una carga administrativa adicional.
- Si no se configura adecuadamente, puede crear un único punto de fallo, provocando que todo el ecosistema falle.

Como implementar este patrón
Un patrón solo define como las aplicaciones deberían de funcionar, pero da carta abierta al programador sobre cómo se debe de implementar, es por eso no existe una sola forma o tecnología para implementar este patrón, por lo que tu podrás desarrollar cada pieza o utilizar algunas herramientas que ya existen en el mercado, donde sin duda, Spring Boot + Netflix OSS son las tecnologías más innovadoras y fáciles de implementar.
Algunas alternativas para el Registro de servicios son:
- Eureka: Parte de Netflix OSS, un conjunto de utilidades desarrolladas por Netflix y liberadas como código abierto.
- Etcd: un almacén de valores-clave distribuido, consistente y de alta disponibilidad que se utiliza para la configuración compartida y el descubrimiento de servicios.
- Consul: una herramienta para descubrir y configurar servicios. Proporciona una API que permite a los clientes registrarse y descubrir servicios. El cónsul puede realizar controles de salud para determinar la disponibilidad del servicio.
- Apache Zookeeper: un servicio de coordinación de alto rendimiento y uso generalizado para aplicaciones distribuidas.
Algunas alternativas para el balanceo de cargas:
- Ribbon: Parte del stack tecnológico de Netflix OSS. El cual permite realizar el balanceo de cargar por medio de Eureka.
- Nginx: pronunciado como “engine-ex”, es un servidor web de código abierto que, desde su éxito inicial como servidor web, ahora también es usado como proxy inverso, cache de HTTP, y balanceador de carga.
Conclusiones
Como hemos podido analizar a lo largo de este artículo, el patrón Service Discovery es uno de los patrones más potentes en arquitecturas de microservicios altamente escalable y que permite librarnos de configurar las direcciones físicas de los servicios, algo sumamente valorado en ambientes cloud, donde tenemos IP flotantes que pueden cambiar de la noche a la mañana o que simplemente requieren del aprovisionamiento dinámico de nuevas instancias.
Excelente articulo, espero algún dia poder implementar este patron.
Hola Alexis, puedes comenzar a implementarlo en proyectos de prueba o personales, no tienes por que esperar que un proyecto te lo solicite.
saludos.
Que buen articulo amigo!
Explicado de forma sencilla y cubre los necesario. Me ha servido bastante para estudiar. Saludos
Me alegra que los artículos que escribo son de ayuda para la comunidad 🙂
Felicidades, un gran Post.
Saludos
Muchas gracias por el comentario Edwin 🙂
Gracias Oscar, artículo sintético y muy clarificador para quienes empezamos recientemente en esto
Hola Gustavo, me da gusto que el material sea de tu utilidad, de la misma forma te invito a que veas mi libro de arquitectura de software donde abordo este patrón con un ejemplo real con Microservicios además de muchos patrones mas.